| Parsing | |
Parsing is the act of reading the file in and then producing what is known as an abstract syntax tree. This tree is then stored in memory and is the basis for the rest of the compiling task. Each instruction in the programming language has a specific syntax and is known as an operator. Each operator may have one or more operands, items which it works on.
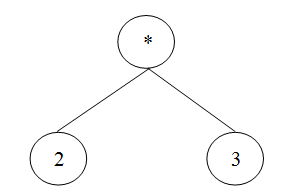
Let's look at converting 2 * 3 into a tree. The expression is the whole line 2 *3. The operator is the * symbol, which stands for multiply. The operands are the two numbers, 2 and 3. The root of the tree will always be the operator. As we have two operands that * acts on, we put these as descendants of the root.
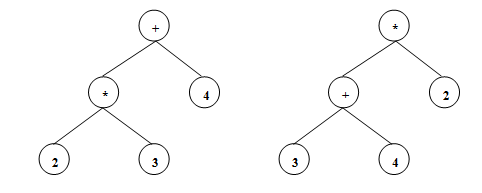
The operator acts on two operands. But why is this useful? Let's look at a more complicated example, 2* 3 + 4.
Which should happen first? Should the * be done first or should the + be done first? The two trees show the two different ways this could be interpreted. However if you read the trees it is clear what is meant. The first tree adds 4 to the sub tree 2 * 3. The second multiplies 2 to the sub tree 3 + 4. Trees are unambiguous, unlike source code. This makes the compilation task much simpler. Also it is heavily used later on in the actual code generation. The compiler clearly knows how to get around this problem when generating the tree in the first place, however this is out of the scope of a-level as the algorithms used in compilers are not simple. The parser, the first job of the compiler, must read in source code as its input and then produce an abstract syntax tree as its output. The interested reader might want to look up how abstract syntax trees are used to perform type checking. |
|

| Links |
| Syntax Analysis |
 Custom Search
Custom Search