| Mergesort | |
Sometimes it is necessary to merge two separate files together in order. For example merging two databases together. The algorithm which is about to be introduced requires that both sets of data must already be in order. If they are not then they must first be ordered before hand, by using insertion sort.
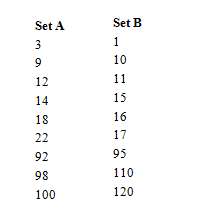
Consider the two sets of data above. These are two separate files which need to be merged into a single file. In order to complete this we must have a new file ready to accept the values. This will be called the result file which will be the size of set A and set B put together. The algorithm is quite simple. It treats both sets of data as a stack where the first element of data is the top of the stack. The first task is to compare the two values. The lowest value is then popped from the stack and placed at the start of the result file.
The first stages of the algorithm is shown above. Each time a value is added to the results, the data set it came from is popped. If there are no values left in one set of data then what ever is left over is simply copied over. Note - In stack talk, to view the top of the stack without removing the value is known as a peek operation. This is used in the pseudo code in the next page.
|
|



| Links |
| Mergesort code |
 Custom Search
Custom Search